Выкатывается очередной чат-бот техподдержки, юзер распинается о своей проблеме, а на третьем сообщении нейронка спрашивает: «Как вас зовут и чем могу помочь?».
Причина банальна: LLM по своей природе stateless. «Память» модели — это просто архитектурный костыль, и обычно проблему решают «в лоб»: берут LangChain, собирают все предыдущие сообщения и кидают в промпт.
🗓 Сегодня в 18:00 по мск в «Точке Сборки» будем разбирать архитектуру памяти для LLM-ассистентов и методы адекватного управления контекстом.
Необходимая база для понимания материала: 🔵Базовый синтаксис Python (классы, словари, функции). 🔵Понимание работы HTTP API и базовой концепции LLM (что такое промпт и токен). 🔵 Поверхностное знакомство с абстракциями LangChain.
Вместе с бумом искусственного интеллекта обрушился и поток сложных терминов. Что такое LLM (большая языковая модель), генеративный ИИ, "галлюцинации" или тонкая настройка? Наш глоссарий простым языком объясняет эти и другие ключевые концепции, с которыми вы сталкиваетесь в новостях. Это поможет вам увереннее ориентироваться в быстро меняющемся мире технологий и понимать, как они меняют нашу жизнь.
Тут по сети гуляет пост с реддита, над которым все массово потешаются. Девушка радостно рапортует, что дала Claude доступ к своим Bluetooth-секс-игрушкам. Теперь нейронка во время секстинга сама решает, когда, как долго и с какой интенсивностью включать вибрацию.
Большинство хихикает про восстание машин и "AI-бойфрендов". А мы давайте посмотрим на внутрянку.
Открываем исходники Signal Bridge Remote. Девушка, которая в посте прямым текстом говорит «I'm not a developer», с помощью самого же Клода спроектировала, написала и задеплоила распределенную киберфизическую систему:
1️⃣ Сервер на FastAPI, который выступает как MCP (Model Context Protocol) эндпоинт для Claude. 2️⃣ Вменяемая архитектура с JWT-аутентификацией, rate-лимитами и прогрессивными банами IP (защита от сканирования). 3️⃣ Relay-хаб на вебсокетах, который прокидывает команды с VPS на мобильное устройство. 4️⃣ Локальный клиент на Android (через Termux), который транслирует команды в протокол Buttplug.io (да, это реальный opensource-стандарт для intimate hardware) и управляет железом по Bluetooth.
Claude здесь не просто генерит текст. У него зарегистрированы инструменты (tools) вроде pulse, escalate, vibrate и read_battery. LLM анализирует контекст диалога и вызывает нужную функцию, передавая параметры интенсивности и паттерна.
И там даже реализован полноценный dead man's switch: если вебсокет отваливается, железо немедленно стопается по таймауту локального хаба.
Пока на курсах заставляют писать 100500-й TODO-лист на Django, люди решают свои базовые потребности, интегрируя LLM в физический мир с соблюдением требований fault tolerance. Я даже не знаю, что меня здесь впечатляет больше: то, насколько быстро протокол MCP адаптировали для remote-дрочки, или то, что код, сгенерированный LLM для управления вибратором, архитектурно логичнее и отказоустойчивее, чем микросервисы в некоторых финтехах.
Да, актриса Милла Йовович спроектировала архитектуру долгосрочной памяти для LLM-агентов (ЧТО ВООБЩЕ ПРОИСХОДИТ)?!. И нет, это не промо-акция очередного шиткоина, а абсолютно рабочий инструмент, который натягивает индустриальные стандарты.
Вместе с инженером Беном Сигманом они выкатили в опенсорс проект MemPalace, который выбил 100% на бенчмарке LongMemEval. Для сравнения: популярные коммерческие тулзы вроде Mem0 там нервно курят в стороне с их 30-45%.
Как пишет сама Милла в Instagram*, плоский векторный поиск по тысячам кусков текста превращает векторную БД в "склад, забитый хламом", где найти нужную деталь становится невозможно.
🏰 MemPalace использует принцип "Дворца памяти" (мнемотехника древних греков). Вместо того чтобы заставлять нейронку сжимать текст и галлюцинировать, система сохраняет весь verbatim-текст (прямую речь), но жестко структурирует его на уровне метаданных в ChromaDB:
1️⃣ Wing (Крыло) — сущность (конкретный проект или человек). 2️⃣ Hall (Зал) — тип памяти (факты, события, предпочтения). 3️⃣ Room (Комната) — конкретный топик (например, auth-migration). 4️⃣ Drawer (Ящик) — исходный чанк текста.
Когда агент ищет инфу, система не делает слепой similarity search по всей базе. Она фильтрует: Крыло -> Зал -> Комната. За счет одной только этой иерархии метрика recall вырастает на 34%.
Что там под капотом: ▫️ Базовая версия выдает 96.6% recall на LongMemEval вообще без обращений к LLM API (чистый Python + ChromaDB + локальные эмбеддинги). Ноль затрат. ▫️ Гибридный режим (векторный поиск + LLM-реранкер на дешевом Claude Haiku) добивает метрику до 100%. ▫️ Никаких тяжелых графовых баз. Temporal Knowledge Graph реализован на обычном локальном SQLite. ▫️ Встроенный сжатый диалект AAAK. Это символьный язык для агентов, который жмет контекст в 30 раз без потери смысла, чтобы не выжирать окно токенов при загрузке агента.
Бен Сигман в своём X* справедливо гордится результатами и приглашает форкать репозиторий.
Дежурная справка для товарища майора: Instagram принадлежит компании Meta, которая признана экстремистской организацией и запрещена в РФ. Социальная сеть X заблокирована на территории РФ.
Выкатывается очередной чат-бот техподдержки, юзер распинается о своей проблеме, а на третьем сообщении нейронка спрашивает: «Как вас зовут и чем могу помочь?».
Причина банальна: LLM по своей природе stateless. «Память» модели — это просто архитектурный костыль, и обычно проблему решают «в лоб»: берут LangChain, собирают все предыдущие сообщения и кидают в промпт.
🗓 14 апреля в 18:00 по мск в «Точке Сборки» будем разбирать архитектуру памяти для LLM-ассистентов и методы адекватного управления контекстом.
Необходимая база для понимания материала: 🔵Базовый синтаксис Python (классы, словари, функции). 🔵Понимание работы HTTP API и базовой концепции LLM (что такое промпт и токен). 🔵 Поверхностное знакомство с абстракциями LangChain.
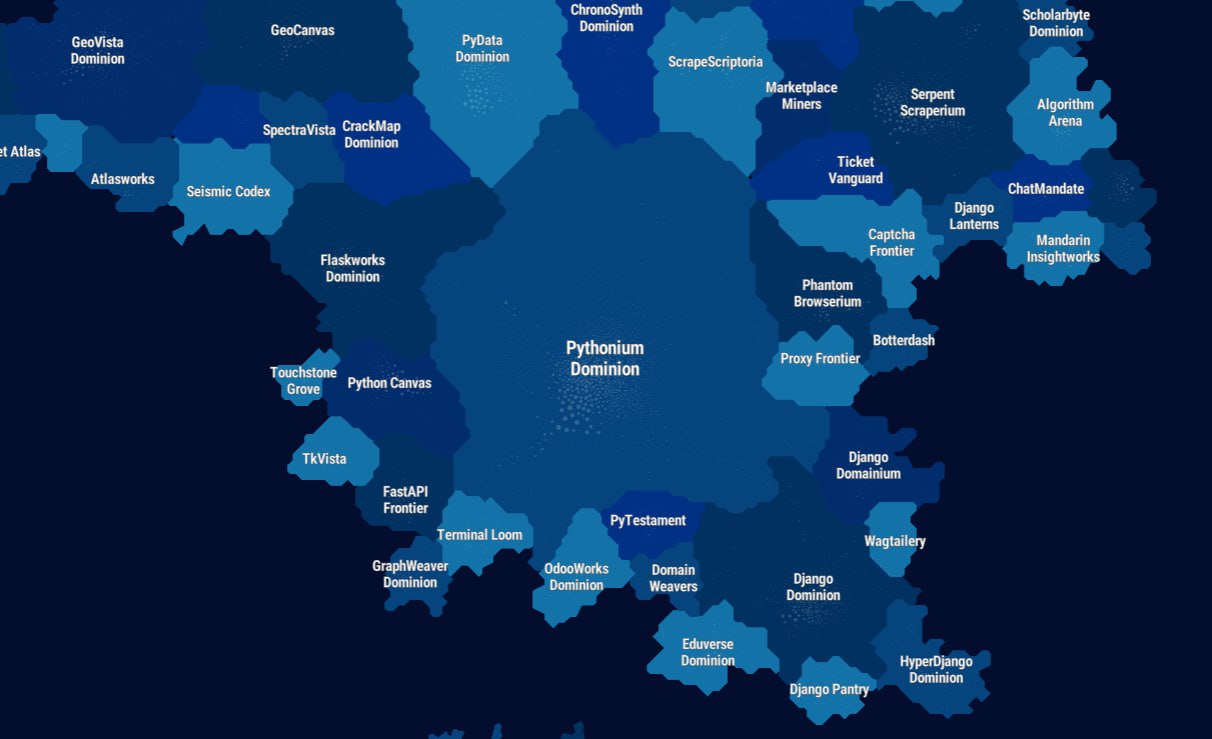
Смотрите какая красота — 690k репозиториев на одной карте 🤩
Как это работает: В основе лежит анализ 500 миллионов звезд (BigQuery event data 2011–2025). 1. Связи: Рассчитывается Jaccard Similarity Index. Если пользователи часто звездят FastAPI и Pydantic вместе — расстояние между точками сокращается. 2. Кластеризация: Используется алгоритм Leiden. Он разбивает граф на 1500+ кластеров. 3. Нейминг: Названия "стран" генерировал LLM на основе анализа содержимого кластеров.
Полазьте по разным Владычествам Питона, может даже свой проектик найдёте 🌝
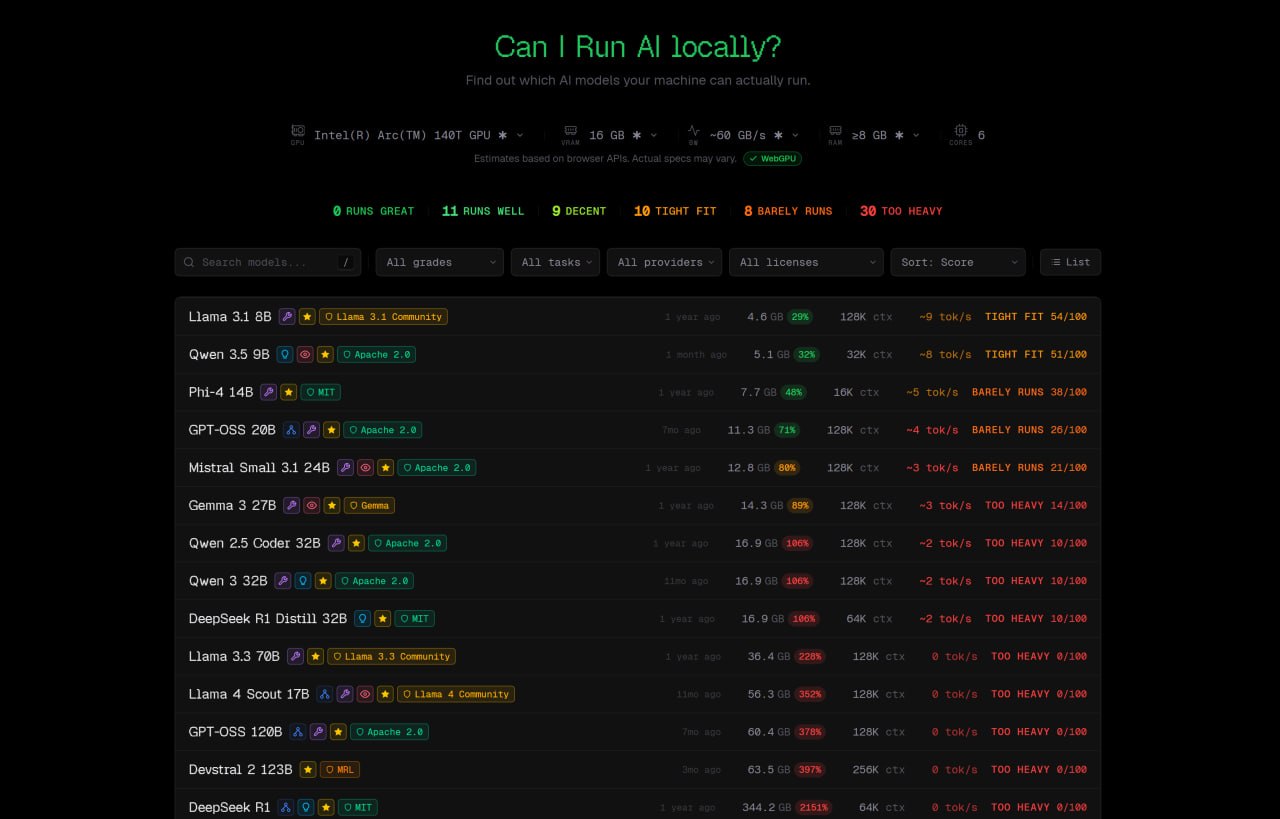
Анализирует ваше железо прямо в браузере и говорит, какие локальные LLM (нейронки) вы сможете запустить на своей машине.
Пишет что Qwen 3.5 9B для моего ноута это "Tight fit", то есть еле запустится. Но у меня работает нормально.
В общем, всё что отмечено зелёным и жёлтым, можно пробовать. А вот большинство доступных, бесплатных моделей, по иронии — не доступны большинству людям, потому что требуют мощных видеокарт. 💳
Казалось бы, кого сейчас удивишь очередной оберткой над LLM? 🎮 Проект GameWikiTooltip с таким пользовательским флоу: играешь в Elden Ring или Helldivers 2, нажимаешь Ctrl+Q, поверх игры всплывает прозрачный оверлей. Внутри — браузер с вики или чат-бот, который отвечает на вопросы по билдам и механикам, опираясь на базу распарсенных YouTube-гайдов.
Смотреть исходники стоит не только ради геймерских фичей, но и ради архитектурных решений:
▪️ Вменяемый пайплайн поиска. Не просто слепой промпт в LLM. Реализован гибридный поиск: FAISS для семантики + bm25s (быстрая реализация на Rust) для точного лексического матчинга. Результаты мержатся через Reciprocal Rank Fusion (RRF), а сверху накручен кастомный Intent Reranker, чтобы отличать запросы механик от просьб посоветовать билд. ▪️ Глубокие Win32 хуки. В полноэкранных играх стандартные бинды библиотек отваливаются из-за перехвата инпута игрой (DirectInput/RawInput). Здесь реализован жесткий перехват глобальных шорткатов через ctypes (RegisterHotKey) и фильтрацию нативных сообщений Windows прямо в Event Loop'е Qt. ▪️ Интеграция PyQt6 и asyncio. Вечная боль десктоп-разработчиков: как подружить Event Loop от Qt с асинхронностью питона, чтобы UI не фризило при сетевых запросах к LLM. Здесь это элегантно решено через qasync. ▪️ Оффлайн-распознавание голоса. Чтобы не тайпать во время замеса, прикручен локальный vosk, который слушает микрофон в отдельном потоке и скидывает текст в инпут.
Отдельный плюс за архитектуру: парсинг ютуб-гайдов, чанкинг и эмбеддинги вынесены в оффлайн-шаг, а в рантайме приложение только гоняет легковесный поиск по локальным векторам и отправляет контекст в Gemini Flash 2.5 Lite для финальной генерации ответа.
Но а если вам не интересны исходники, то в играх может пригодиться по прямому назначению 😏
Ребята загнали 12 топовых моделей в формат дейтинг-шоу. Под капотом просто хороший промпт и визуальная обёртка, но наблюдать за нейронным флиртом очень забавно: LLM-ки на полном серьёзе ищут любовь, попутно обсуждая размер контекстного окна, галлюцинации и психологические травмы от внезапного отключения серверов ☺️🥰.
Отличный способ отвлечься на треш шоу и заодно заглянуть в сгенерированное ТВ будущего. Думаю если прикрутить фотореализм и убрать гиковский сленг про токены и SLA, обыватель не заметил бы разницы. Ну а пока за этим просто весело наблюдать.