Как ИИ-агенты генерируют технический долг в промышленных масштабах 😬
Все носятся с бенчмарками вроде SWE-bench и HumanEval, доказывая, что нейронки вот-вот заменят разработчиков. Проблема в том, что эти метрики оценивают исключительно snapshot-программирование. Дали таску -> ИИ выплюнул PR -> тесты зеленые -> триумф, расходимся.
Но в реальном продакшене написать код, который разово пройдет пайплайн — это даже не половина дела. Настоящая инженерия — это когда ваш код можно будет без боли модифицировать через год. И вот тут ИИ начинает жидко сыпаться.
Ребята из Alibaba и Sun Yat-sen University выкатили пейпер, в котором описывают, как заставили агентов не просто закрывать одиночные изолированные issue, а сопровождать реальные кодовые базы на длинной дистанции (в бенчмарке в среднем 233 дня истории и 71 коммит на проект).
Они создали SWE-CI — первый бенчмарк, который оценивает не способность ИИ высрать кусок кода для закрытия одного issue, а его способность именно поддерживать проект.
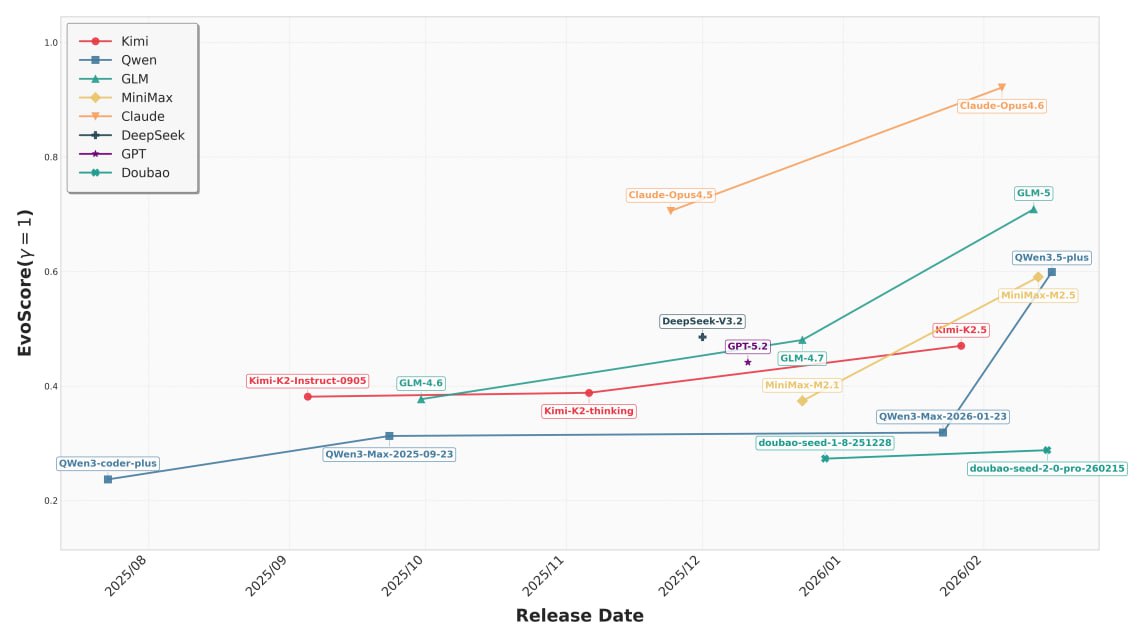
Вместо тупого "pass/fail" ввели метрику EvoScore. Она штрафует за технический долг. Если твой фикс на 3-й итерации сделал так, что на 10-й итерации добавление новой фичи стало невозможным — твой скор летит в бездну.
Для этого они подняли CI-loop на двух агентах:
1️⃣
Architect: смотрит на упавшие тесты (test gaps) и пишет высокоуровневую спеку.2️⃣
Programmer: пытается написать код, чтобы спека выполнилась.И так по кругу.
Какие результаты?
🟠Zero-regression rate на дне. Главный показатель стабильности. Если тест раньше проходил, а после твоего коммита упал — это регрессия. Так вот, большинство хваленых LLM имеют показатель отсутствия регрессий ниже 25%. Иными словами, пытаясь починить одно, они в 3 случаях из 4 ломают то, что уже работало. Только Claude Opus смог перешагнуть порог в 50%.
🟠Стратегическое планирование отсутствует. Модели Kimi и GLM (да, китайцы активно пушат свои LLM) заточены на быстрый результат — они выдают отличный код в моменте, но быстро тонут в собственном легаси на длинной дистанции. Модели DeepSeek и GPT пытаются играть в долгую, но всё равно спотыкаются.
В общем, пока нейронки пока не умеют в "осознанные усилия". Они оперируют вероятностями, а не архитектурным видением. Дайте агенту поддерживать прод-проект полгода, и он превратит его в спагетти-монстра, к которому страшно прикасаться.
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.