Как ИИ-агенты генерируют технический долг в промышленных масштабах 😬
Все носятся с бенчмарками вроде SWE-bench и HumanEval, доказывая, что нейронки вот-вот заменят разработчиков. Проблема в том, что эти метрики оценивают исключительно snapshot-программирование. Дали таску -> ИИ выплюнул PR -> тесты зеленые -> триумф, расходимся. Но в реальном продакшене написать код, который разово пройдет пайплайн — это даже не половина дела. Настоящая инженерия — это когда ваш код можно будет без боли модифицировать через год. И вот тут ИИ начинает жидко сыпаться.
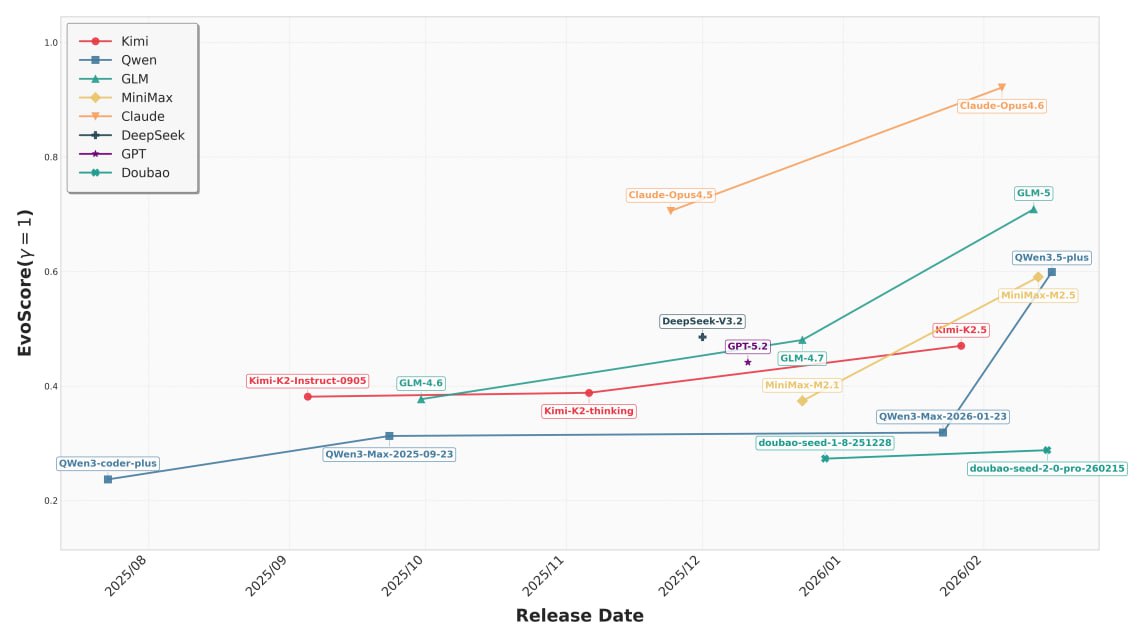
Ребята из Alibaba и Sun Yat-sen University выкатили пейпер, в котором описывают, как заставили агентов не просто закрывать одиночные изолированные issue, а сопровождать реальные кодовые базы на длинной дистанции (в бенчмарке в среднем 233 дня истории и 71 коммит на проект).
Они создали SWE-CI — первый бенчмарк, который оценивает не способность ИИ высрать кусок кода для закрытия одного issue, а его способность именно поддерживать проект. Вместо тупого "pass/fail" ввели метрику EvoScore. Она штрафует за технический долг. Если твой фикс на 3-й итерации сделал так, что на 10-й итерации добавление новой фичи стало невозможным — твой скор летит в бездну.
Для этого они подняли CI-loop на двух агентах: 1️⃣ Architect: смотрит на упавшие тесты (test gaps) и пишет высокоуровневую спеку. 2️⃣ Programmer: пытается написать код, чтобы спека выполнилась. И так по кругу.
Какие результаты? 🟠Zero-regression rate на дне. Главный показатель стабильности. Если тест раньше проходил, а после твоего коммита упал — это регрессия. Так вот, большинство хваленых LLM имеют показатель отсутствия регрессий ниже 25%. Иными словами, пытаясь починить одно, они в 3 случаях из 4 ломают то, что уже работало. Только Claude Opus смог перешагнуть порог в 50%. 🟠Стратегическое планирование отсутствует. Модели Kimi и GLM (да, китайцы активно пушат свои LLM) заточены на быстрый результат — они выдают отличный код в моменте, но быстро тонут в собственном легаси на длинной дистанции. Модели DeepSeek и GPT пытаются играть в долгую, но всё равно спотыкаются.
В общем, пока нейронки пока не умеют в "осознанные усилия". Они оперируют вероятностями, а не архитектурным видением. Дайте агенту поддерживать прод-проект полгода, и он превратит его в спагетти-монстра, к которому страшно прикасаться.
Андрей Карпаты (ex-Tesla AI, ex-OpenAI) выдал очередную базу в новом посте. Суть простая: программирование изменилось до неузнаваемости. И это произошло не плавно, а резким скачком буквально за последние пару месяцев.
По его мнению, до декабря AI-агенты для написания кода по сути не работали. А сейчас — работают. Модели пробили потолок качества, научились держать долгосрочный контекст, проявлять упорство и самостоятельно продираться через сложные, объемные задачи.
👉🏻 Практический кейс Андрея: На выходных ему понадобился локальный дашборд для аналитики видео с домашних камер. Он не открыл редактор, а написал агенту один промпт на английском:
Вот IP, логин и пароль от моего локального сервера. Зайди, настрой SSH-ключи, накати vLLM, скачай и запусти бенчмарк Qwen3-VL. Подними серверный эндпоинт для инференса видео, накидай базовый Web UI, протестируй всё это, заверни сервисы в systemd, сохрани для себя заметки по памяти и напиши мне Markdown-отчет.
Агент ушел шуршать на 30 минут. За это время он сам наткнулся на кучу багов, сам нагуглил решения, написал код, подебажил, поднял сервисы и вернулся с полностью готовым результатом. Карпаты к коду даже не притронулся. То, что еще три месяца назад было пет-проектом на все выходные, теперь — фоновая таска на полчаса, которую ты запускаешь и идешь пить кофе.
🤖 Agentic Engineering По мнению Карпаты, мы прямо сейчас прощаемся с концепцией "человек печатает инструкции в текстовом редакторе".
Теперь разработка — это когда ты поднимаешь инстансы ИИ-агентов, ставишь им задачи на естественном языке и параллельно менеджишь и ревьюишь их работу. Выигрывает тот, кто научится забираться всё выше по слоям абстракции и управлять долгоживущими оркестраторами, которые контролируют толпу параллельных ИИ-кодеров, выдавая им нужные тулзы и контекст.
⚖️ Где здесь человек? Это всё еще не магия "сделай мне кнопку бабло". Агентам по-прежнему критически нужны: 🟢 Высокоуровневый дирекшн и архитектурное видение. 🟢 Инженерный вкус и оценка (тот самый judgement). 🟢 Итеративные подсказки.
Лучше всего это работает там, где задача имеет жесткую спецификацию, а функциональность можно легко верифицировать тестами. Главный навык сейчас — интуиция в декомпозиции. Вы должны уметь разбить сложную систему на атомарные куски, которые можно безопасно делегировать агенту, и контролировать их стыки.
Собственно, синтаксис больше не стоит почти ничего. Архитектура, декомпозиция и умение управлять сложными абстракциями — стоят всего.
🤖 Gemini Pro 3.1: новый рекордсмен Google в тестах ИИ
Google анонсировала Gemini 1.5 Pro — следующее поколение своей флагманской модели. Система демонстрирует рекордные результаты в тестах на понимание текста, кода, аудио и видео (MMLU, GPQA, MATH). Ключевое улучшение — увеличенный контекст до 2 миллионов токенов, что позволяет модели анализировать огромные объемы данных: час видео, 22 часа аудио или свыше 1.4 млн слов за один запрос. Это открывает новые возможности для глубоких исследований и сложных аналитических задач.
Google представляет Gemini 3.1 Pro — более совершенную модель для решения самых сложных задач
▶️ Компания Google выпустила Gemini 3 Pro 19 ноября, а сегодня, ровно через три месяца, представила Gemini 3.1 Pro. По словам представителей Google, эта модель «представляет собой шаг вперед в области базовых рассуждений» и является «более интеллектуальной и функциональной основой для решения сложных задач».
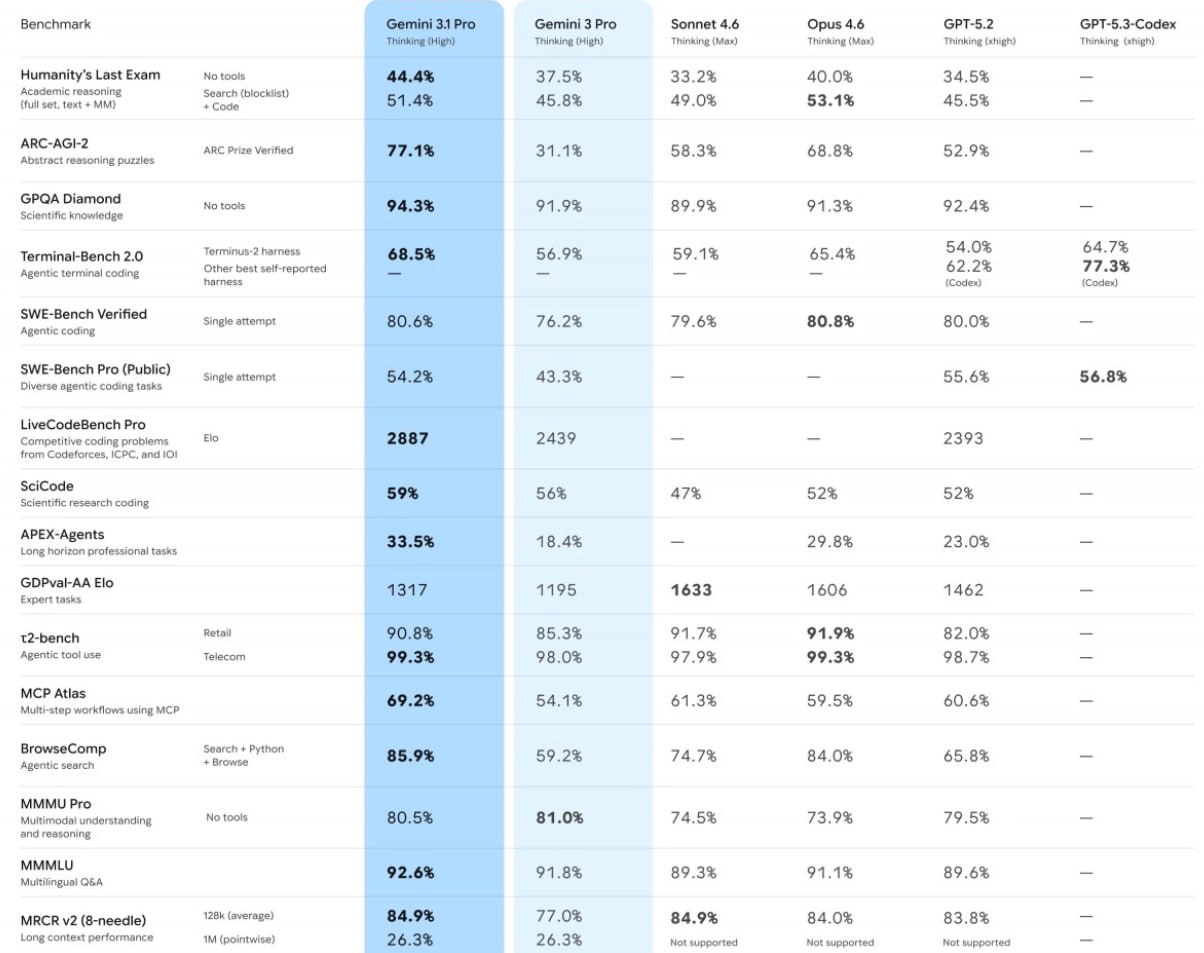
▶️ По словам представителей Google, это отражается на результатах различных тестов искусственного интеллекта. На изображении ниже вы можете сравнить Gemini 3.1 Pro с другими новейшими моделями конкурентов Google, а также с Gemini 3 Pro.
▶️ Google обращает особое внимание на производительность Gemini 3.1 Pro в тесте ARC-AGI-2, который описывается как «бенчмарк, оценивающий способность модели решать совершенно новые логические задачи». Как видите, Gemini 3.1 Pro показал лучшие результаты.
▶️ По словам представителей Google, эта новая модель «предназначена для решения задач, где простого ответа недостаточно», поскольку она использует «сложные алгоритмы» для решения «самых сложных задач». Улучшенный интеллект Gemini 3.1 Pro может помочь в практических задачах, когда «вам нужно четкое визуальное объяснение сложной темы, способ систематизировать данные в единое представление или воплотить в жизнь творческий проект».
▶️ С сегодняшнего дня Gemini 3.1 Pro доступен всем пользователям через приложение Gemini, но подписчики Google AI Pro и Ultra получат более высокие лимиты. Gemini 3.1 Pro также доступен в NotebookLM, но только для подписчиков Google AI Pro и Ultra.