Размышления о цифровой трансформации бизнеса, управлении в IT и финтехе.
Поддержать автора можно тут: https://t.me/tribute/app?startapp=dFU2
Feedback: @IstominGerman
Коммуникация — это выбор режима, а не одна техника. Главная проблема статьи — в том, что она продаёт один набор паттернов как универсальное решение.”. Но реальная коммуникация — это не один режим, а набор переключателей:
В кризисе и на операционном уровне — да, BLUF рулит, потому что важна скорость и однозначность.
В обучении и менторстве — работает сократический подход: вопросы, совместный разбор, построение контекста перед выводом.
В стратегических обсуждениях и продуктовых решениях — критичны именно “лишние” слои контекста: история решений, отклонённые варианты, риски.
Грамотно построенный диалог — не тот, где всегда “сначала выдаёт вывод”, а тот, где осознанно выбирается режим под цель: где-то быстро дать ответ, где-то построить понимание, где-то — выровнять глубину у команды, даже ценой времени.
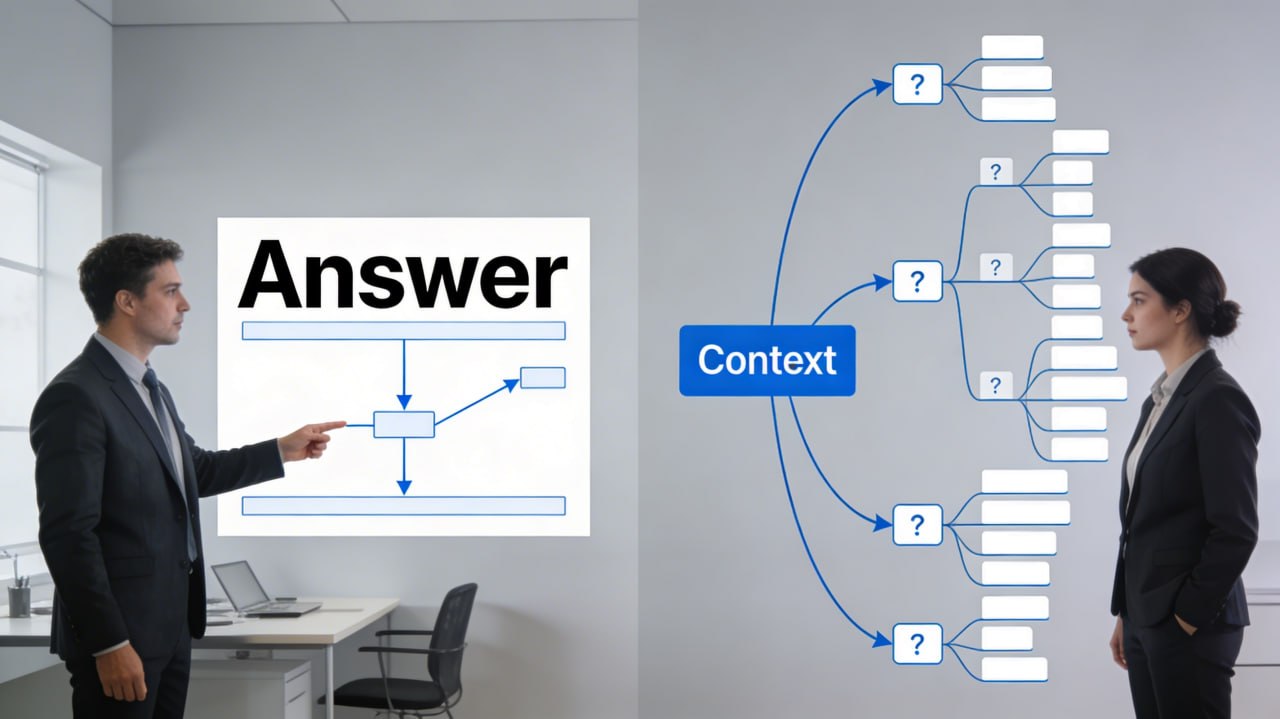
В оригинальной статье автор предлагает три правила “правильной” коммуникации: BLUF, “just in time” контекст и “top‑down bridge”. На бумаге звучит красиво, но как только вы выходите за рамки простых задач и маленьких команд, эти советы начинают буксовать. ☝️ BLUF: “сначала вывод” — не всегда благо
Идея BLUF проста: начни с главного вывода, а детали расскажи потом. В военной среде и в коротких статус-апдейтах это действительно работает — когда контекст у всех примерно одинаковый и цена задержки решения высока.
Но в живой коммуникации есть нюанс: у собеседника уже есть свой внутренний контекст, гипотезы и ожидания. Если вы в первой же фразе кидаете вывод, который конфликтует с его картиной мира, вы получаете не “эффективность”, а мгновенный когнитивный диссонанс и защитную реакцию. Человек не слушает аргументы, он внутренне спорит с вашим первым предложением.
Давайте разберемся как должно быть устроено объяснение. Сначала выстраивается контекст через вопросы и уточнение предпосылок, а потом формируется вывод. Это ровно то, что делает сократический метод: через вопросы вытаскивает исходные предположения, помогает человеку самому прийти к новой мысли, а не просто “проглотить” чужой тезис. В результате понимание глубже и устойчивее, чем от “вывода в лоб”. Тем же самым пользуются хорошие учителя в школе, просто мы об этом забыли.
BLUF хорош как один из режимов, но как “единственно правильный способ” он превращается в источник недопонимания, особенно там, где нужно не просто донести решение, а изменить модель мышления собеседника.
☝️ “Just in time context”: глубина — не балласт
Второй тезис статьи — “давайте столько контекста, сколько нужно для решения текущей проблемы, и не грузите людей своей глубиной знаний”. Логика понятна: когнитивная нагрузка ограничена, людям сложно переваривать лишнюю информацию. Но из этого делается слишком радикальный вывод — будто глубина мешает.
В больших организациях конфликты чаще рождаются не из-за “лишнего контекста”, а как раз из-за разной глубины понимания у участников. Один мыслит на уровне архитектуры, другой — на уровне тикетов, третий — на уровне бизнес-метрик. Все вроде говорят на одном языке, но за словами стоят разные модели, и отсюда — постоянные “мы вас не так поняли”.
Если в такой ситуации вы обрезаете контекст “под задачу прямо сейчас”, вы экономите 10 минут сегодня и теряете часы/дни завтра — на разборе последствий решений, принятых из разных картин мира.
Нормальный time‑management в коммуникации — это не “урезать глубину”, а выделить время на передачу цепочки рассуждений: от исходных допущений до решения. Да, это дороже по времени на входе, но это инвестиция: дальше человек уже в контексте, понимает вашу логику и может сам принимать согласованные решения без постоянного “подскочи созвониться”.
☝️ Top‑down bridge: шаги верные, но половина моста недостроена
Третий тезис — “строить мост сверху вниз”: отталкиваться от того, что человек уже знает, и постепенно углубляться. С этим сложно спорить: если разрыв в глубине огромный, попытка за один разговор протащить человека через всю вашу модель мира обречена. Лучше дробить: сначала высокоуровнево, потом по мере необходимости детализировать. Но здесь есть подвох. Если вы ограничиваетесь только верхним уровнем и не закладываете план по устранению пробелов в понимании, вы застрянете в вечном режиме “я тебе тезис, ты мне поверхностное согласие”. В какой-то момент вы неизбежно придёте к конфликтам из пункта 2.
То есть “top‑down bridge” работает только в связке:
мы начинаем с верхнего уровня — чтобы собеседник не утонул в деталях;
но осознанно планируем: где и когда пройдёмся по цепочке логики глубже, чтобы выровнять модель мира.
И вот тут круг замыкается: без устранения пробелов в глубине трудно сделать честный BLUF (п.1), который не вызовет отторжения.
👉Bottom line up front. Когда вас просят что-то объяснить, основной вывод должен быть в первой же фразе, и только потом идти дополнительный контекст. А многие поступают наоборот – вместо прямого ответа пытаются подробно воспроизвести рассуждения, которые к нему приводят. 👉Just in time context. Не нужно пытаться сходу вывалить весь возможный контекст. Давайте его ровно столько, сколько нужно, чтобы собеседник мог решить свою текущую проблему. А чем глубже вы понимаете какую-то тему, тем сложнее удержаться от того, чтобы погрузить в нее человека. 👉The top-down bridge. Когда вы насыпаете кому-то контекст, отталкивайтесь от того, что они сейчас знают, и постепенно углубляйтесь в детали, отстраиваясь от этого.
Прочитал я вот такую статью и понял что весьма не согласен с ее утверждениями, т.к. это какой "конь в вакууме", поэтому решил написать свои мысли почему важно как раз наоборот.
Это интегрированная платформа, которая ставится на ваше железо или виртуализацию (собственную или арендованную) и работает в периметре компании.
По сути, это «облако у вас в дата‑центре»: Kubernetes‑кластер + управляемые БД + объектное S3‑хранилище + сервисы Yandex Cloud on‑premises.
Технологическая основа
Базируется на Kubernetes, что позволяет использовать привычные подходы к деплою микросервисов, Helm, GitOps и т.п.
В комплекте специализированная ОС для контейнерных нагрузок, IAM, политики безопасности, секрет‑менеджмент, единая консоль (UI) с админским и пользовательским режимами.
Встроенные сервисы
Управляемые базы: PostgreSQL, ClickHouse, Kafka, плюс векторные БД для RAG‑сценариев; планируются OpenSearch и Trino.
Объектное S3‑хранилище для документов, медиа, бэкапов, логов и данных для ИИ‑нагрузок.
On‑prem‑сервисы Yandex Cloud: уже доступны SpeechSense (речевая аналитика) и DataLens (BI), в ближайшее время — Yandex AI Studio для разработки ИИ‑приложений и агентов.
Фокус на AI и аналитике
Есть инструменты управления доступом к GPU и высокопроизводительным сетям (например, InfiniBand) для задач инференса и распределённых ИИ‑нагрузок.
Платформа позиционируется как ядро внутренней developer‑платформы (Internal Developer Platform) для гибридной инфраструктуры: часть нагрузок — в приватном контуре, часть — в публичном облаке.
Лицензирование и сценарии применения
Поставляется как коробочный продукт по срочной или бессрочной лицензии, лицензирование считается по количеству ядер CPU; все инфраструктурные компоненты входят в лицензию, а такие вещи как AI Studio, DataLens, SpeechSense покупаются отдельно.
Основные сценарии: запуск и масштабирование микросервисных и ИИ‑приложений в закрытом контуре, построение внутренних облачных платформ, корпоративных веб‑сервисов, аналитических витрин и RAG‑решений.
Яндекс поделился практическим опытом, как они научились приоритизировать ML-трафик в InfiniBand‑сетях GPU‑кластеров, чтобы важные задачи не «проседали» по скорости из‑за соседних запусков.
Ключевые моменты:
InfiniBand использует централизованный Subnet Manager (OpenSM), который управляет адресацией, маршрутизацией и QoS‑политиками через связку Service Level (SL) и Virtual Lanes (VL).
QoS строится так: трафик разных типов «красят» в разные SL, которые маппятся в VL с разным приоритетом и весами; в тестовой схеме SL1 получает 80% полосы, SL0 — 20%.
В кластерах YATI несколько обучений разных пользователей делят одну InfiniBand‑фабрику, поэтому без QoS крупные и критичные обучения легко «топятся» параллельными задачами.
На FatTree‑кластерe с HDR они сначала не увидели эффекта, пока искусственно не создали переподписку (отключили часть spine‑коммутаторов), после чего трафик SL1 реально начал выдавливать SL0 при конкуренции.
В DragonFly+ всё сложнее: там маршрутизация использует разные VL для прямого пути и +1/+3 hop, чтобы избежать credit loop deadlock в lossless‑сети, поэтому SL→VL‑маппинг становится частью Control Plane, а доступное число «красок» фактически сокращается.
В итоге Яндекс превратил QoS в продуктовый механизм: планировщик обучения помечает крупные обучения (по порогу GPU на кластер, настраиваемому для каждого кластера) как приоритетные, агент на хосте перекрашивает их трафик в SL1, остальные идут в SL0 — даже если пользователь пытался проставить свои SL.
Дальше этот же подход планируют использовать для разведения обучения и мультихостового инференса, отдавая приоритет real‑time‑инференсу по сети.
QoS в InfiniBand — это не просто «очереди на порту», а тесная связка с топологией и routing engine (особенно в DragonFly+), иначе легко получить либо отсутствие эффекта, либо ризик deadlock’ов.
В классическом DevOps много говорят про «совместную ответственность», но на практике это часто вырождается в анти‑паттерн: «когда за всё отвечают все — не отвечает никто». Инциденты висят часами, продукт деградирует, а команды теряются в вопросе «кто это вообще чинит?».
Совместная ответственность без явного владельца превращается в матрицу безответственности: метрики падают, пользователи страдают, а в ретро обсуждаются только «процессы» и «коммуникации». Явное владение продуктом делает ровно противоположное — у каждой системы и каждого слоя есть конкретный владелец, который отвечает за результат, а не только «поучаствовать». Для этого платформенные команды должны мыслить как продуктовые: отвечать за надёжность, UX платформы, документацию и понятные интерфейсы, а не только за «инфру и тулзы».
Вместо неформальных договорённостей «напиши Пете, он когда‑то это делал» появляются чёткие интерфейсы: API, SLO, каталоги сервисов, онбординг‑гайды и стандартные процессы изменения. Команды двигаются быстрее не за счёт обхода контроля, а за счёт встроенного контроля — чеклисты, автоматические проверки, стандартные пайплайны, а не ручные согласования в чатах. Гибридная работа и распределённые команды усиливают этот запрос в разы: когда вы редко встречаетесь офлайн, не спасают «договорились на словах». Нужны прозрачные политики, асинхронные процессы и внятное целеполагание через OKR (цели и ключевые результаты), где у каждой цели есть измеримые ключевые результаты и понятный владелец. Тогда не только понятно «кто делает», но и «что считается успехом» на уровне продукта и платформы.
Практический инструмент, который хорошо заходит в таких условиях, — матрица ответственности RACI (Responsible, Accountable, Consulted, Informed). Она помогает явно зафиксировать: кто исполняет работу (R), кто несёт конечную ответственность за результат (A), кто подключается как эксперт (C) и кто просто должен быть в курсе (I). В распределённых продуктовых и платформенных командах RACI даёт общий язык, который вытаскивает ответственность из «серой зоны» и превращает DevOps из лозунга про «совместную боль» в управляемую систему.
Облака как двигатель цифровой трансформации в России 🚀
Российский облачный рынок в 2025 году вырос на 30–35% и вплотную подошёл к отметке ~400 млрд ₽ – облака стали самым быстрорастущим сегментом ИТ-рынка и фактически базовой инфраструктурой для ИИ-проектов и цифровой трансформации бизнеса.
Взрывной интерес к ИИ: от экспериментов с генеративными моделями к внедрению ИИ-агентов в процессы поддержки, продаж, логистики и аналитики.
Ужесточение требований к защите данных и суверенности: бизнесу всё сложнее поддерживать нужный уровень безопасности on-prem, облака предлагают сертифицированные контуры и готовые сервисы.
⛅ Yandex Cloud и эволюция архитектуры:
Сильный дрейф к гибридной модели: сочетание собственных мощностей и публичного облака, единая сеть и сквозной мониторинг.
Упор на генеративные модели и ИИ-агентов как сервис: готовые LLM, инструменты для оркестрации цепочек, интеграция с данными заказчика.
☁️ Тренд 2026: из «ферм виртуализации» в облачные платформы:
Консолидация зоопарка кластеров виртуализации в полноценные облака с единой панелью, API и сервисами управления стоимостью (FinOps).
Для заказчика это переход от «виртуалок по запросу» к модели платформы: каталоги сервисов, PaaS, управляемые базы, очереди, мониторинг, пайплайны данных.
⛔️ Импортозамещение и уход от VMware:
Массовый отказ от VMware и встраивание российских стеков виртуализации и контейнеризации стали отдельным драйвером миграции в российские облака.
Критический вопрос на 2026–2027 годы: как совместить быстрый переезд, устойчивость и прозрачную экономику потребления ресурсов.
Экономика данных – данные как актив и основа продуктовой стратегии.
DSLM (Data & Software Lifecycle Management) – управление жизненным циклом данных и ПО как единой системой.
Low-code / no-code – ускорение вывода цифровых продуктов, особенно на уровне внутренних back-office и фронтов.
AI-агенты – автоматизация бизнес-процессов поверх корпоративных систем.
XaaS – «всё как сервис»: от инфраструктуры до отраслевых ИТ-платформ.
Все эти тенденции сходятся в одной точке: российские облака перестают быть «дешёвой виртуалкой» и становятся движком цифровой трансформации — от пилотов ИИ к промышленной эксплуатации в защищённых, управляющих затраты платформах.
Теперь в DBaaS есть до 7 ежедневных бэкапов с хранением за последние 7 дней, которые можно самостоятельно поднять в виде нового кластера без обращения в техподдержку — исходный кластер при этом продолжает работать, так что спокойно тестируем восстановление и планируем переключение без простоя. Для PostgreSQL добавили Point-in-Time Recovery, чтобы откатываться максимально близко к моменту логической ошибки или кривого деплоя.
Инфраструктура тоже получила апгрейд: к Москве-1 добавилась вторая зона доступности в новом ЦОД в Медведково (Москва-2) с теми же тарифами и функционалом — можно локализовать данные, раскидывать нагрузку между площадками и собирать более устойчивую архитектуру под требования бизнеса и регуляторов.
Из интересного по метрикам: 60% клиентов выбирают минималку 1 vCPU / 1 GB RAM / 20 GB, ещё 21% берут 2 vCPU / 4 GB RAM / 80 GB — спрос явно уходит в сторону сбалансированных по цене и производительности конфигураций для девелопмента и продакшена.
Один из самых сложных навыков фасилитатора — помочь команде прийти к общему решению. Ведь надо оставаться объективным, дать каждому высказаться — и при этом не затягивать обсуждение до бесконечности.
Вот 5 проверенных техник:
1️⃣ 1-2-4-All Сначала каждый думает в одиночку (1 мин) → потом обсуждает в парах (2 мин) → затем в четвёрках (4 мин) → и наконец делится с группой (5 мин). Такой постепенный переход от личного к общему помогает избежать группового мышления: к моменту общего обсуждения у каждого уже есть своя сформированная позиция.
2️⃣ Тридцать пять Каждый выбирает карточку с понравившейся идеей. Затем в парах участники распределяют 7 баллов между двумя идеями на руках. После 5 раундов смены партнёров суммируем баллы — побеждает идея с наибольшим числом очков. Быстро, честно, систему не обмануть.
3️⃣ Купи Фичу/идею Участники получают «игровые деньги» и могут «купить» понравившиеся фичи или идеи/решения из списка. Хитрость в том, что цены намеренно высокие — купить что-то в одиночку почти невозможно. Команда вынуждена договариваться, объяснять друг другу свою позицию и искать компромисс. В процессе этих переговоров и рождается настоящий консенсус.
4️⃣ Голосование точками Каждый получает одинаковое количество голосов-точек и распределяет их по вариантам. Можно поставить все точки на один вариант, если вы в нём уверены, или распределить между несколькими.
5️⃣ Голосование пальцами Голосуем пальцами по шкале от 1 до 5: 5 — «отличная идея, поддерживаю!», 1 — «категорически против, нужно искать другое решение». В отличие от точечного голосования, эта техника показывает не просто выбор, а степень поддержки. Если консенсус не достигнут — обсуждаем, дорабатываем идею и голосуем снова.
Какую технику выбрать — зависит от контекста и задачи. Но главное: не нужно ждать, пока команда сама придёт к согласию. Иногда достаточно просто задать правильный процесс.
А какие техники используете вы? Делитесь в комментариях 👇