Runway неожиданно зашли в нишу реалтайм-ассистентов. Под капотом — их новая world-модель GWM-1, хотя по ощущениям это шустрая LLM + диффузия с кучей костылей для реалтайм-видео сверху.
Качество неплохое, но есть нюансы: в конце фразы — кат и переключение на базовую анимацию, глаза в фотореализме немного плывут из-за дистилляции.
Из интересного: — Аватар создаётся из одной картинки — Кастомный голос и промпт — Можно подключить свою базу знаний и встроить на сайт
На тесты дают 30 минут разговора — для Runway это неожиданная щедрость. Подробности в блоге Runway, попробовать — на app.runwayml.com, API для разработчиков — на dev.runwayml.com.
🎧 ИИ научился слышать видео — и генерировать звук под каждый кадр.
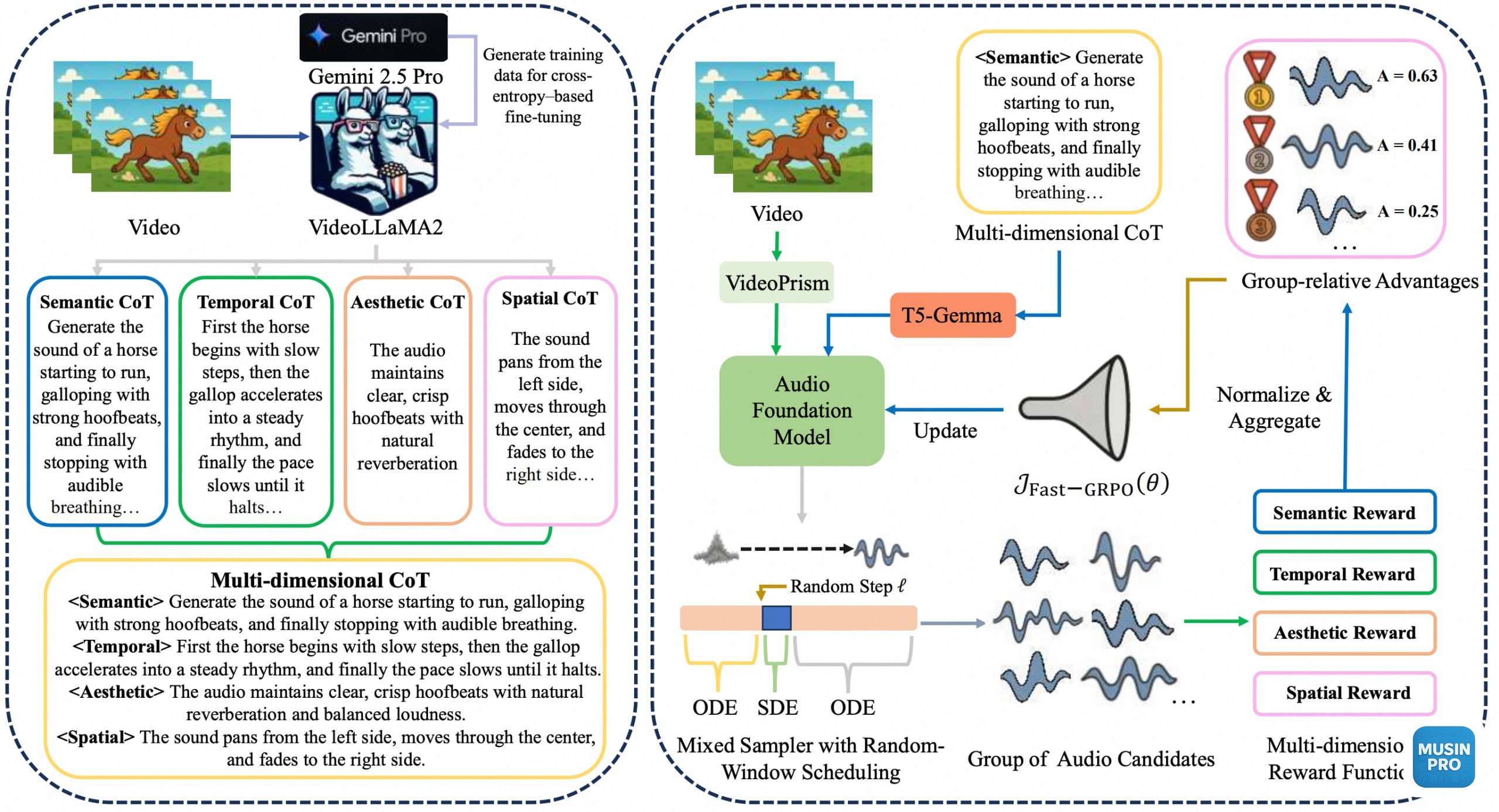
Лаборатория Qwen выпустила PrismAudio — модель, которая смотрит на видео и сама придумывает звуковую дорожку. Не просто "что-то похожее", а с правильным таймингом, пространством и эстетикой.
Фишка в архитектуре: вместо одного монолитного мозга — 4 специализированных модуля рассуждений: • 🟠 что за звуки на экране • 🟠 когда именно они должны звучать • 🟠 насколько естественно • 🟠 где в стереопанораме
Каждый модуль обучается отдельно — поэтому качество по всем осям одновременно.
Результат: 0,63 секунды на генерацию 9-секундного видео. Лицензия MIT — открытый код.
Нюанс: извлечение признаков жрёт ~43 ГБ видеопамяти. Не для домашнего сервера.