Odyssey представила Odyssey-2 Max, свою крупнейшую модель мира. Формально это родственник видеогенераторов, но логика другая: система не собирает готовый ролик по промпту, а шаг за шагом предсказывает следующее состояние сцены и позволяет продолжать симуляцию в реальном времени.
Компания продает не «красивое видео», а управляемую среду, где будущее кадра зависит от предыдущего состояния и действия пользователя. Для игр это звучит как интерактивная сцена. Для робототехники как тренировочная среда. Для обороны и медицины как повод внимательно смотреть на качество проверки, потому что красивая физика на демо ещё не равна надежной модели причинно-следственных связей.
В релизе есть несколько конкретных чисел. 2 Max примерно в 3 раза крупнее 2 Pro и обучалась с 10-кратным ростом вычислений. На физическом разделе VBench 2 результат вырос с 49,67 до 58,52. На PAI-Bench Physics с 91,67 до 93,02. Компания также утверждает, что все показанные симуляции работали в реальном времени и могли продолжаться более 120 секунд.
Технически модель построена как авторегрессионный диффузионный трансформер. Важные детали: длинный контекст, каузальное внимание, управление действиями через латентные представления, сопоставление потоков в непрерывном латентном пространстве и сокращение числа шагов подавления шума. Обучение шло на нескольких сотнях NVIDIA B200.
Наиболее интересная часть здесь не картинка. Создатели проводят аналогию с языковыми моделями: предсказание следующего токена дало системам способность имитировать рассуждение, а предсказание следующего состояния мира должно дать физическую интуицию. Это амбициозная гипотеза, и она хорошо объясняет, почему вокруг моделей мира сейчас столько инвесторского и исследовательского интереса.
Но проверять всё это нужно осторожно. VBench и PAI-Bench оценивают согласованность сгенерированного видео, а не пригодность системы для реальной робототехники или научного моделирования. Стабильный фон, гладкое движение и правдоподобная механика полезны, но они не доказывают, что модель понимает причинные связи в строгом смысле.
Сравнение с Sora, Veo, Kling и Runway тоже устроено выгодно для разработчиков 2 Max. Эти системы исключены из таблицы как двунаправленные видеомодели, потому что они не рассчитаны на интерактивное предсказание будущих состояний. Аргумент логичный, но поле сравнения получается меньше: речь идет о категории, которую сама компания и пытается закрепить как отдельную.
Еще один момент: модель доступна в частной бете для партнеров. Значит, независимая проверка пока ограничена. Главные вопросы будут в длинных сценариях, где пользователь делает странные действия, сцена постепенно накапливает ошибки, а физическая правдоподобность начинает конфликтовать с управляемостью.
Релиз всё равно значимый. Генеративное видео постепенно делится на две линии: производство готового визуального контента и интерактивные симуляторы среды. Первая линия обслуживает медиа. Вторая может стать основой для тренажеров, игр, агентов, робототехники и систем планирования.
Гонка за моделями мира стала отдельным направлением. Там конкурирует не столько красота кадров, сколько устойчивость причинности, горизонт симуляции, управляемость и цена генерации в реальном времени.
OpenAI предлагает призму, через которую государство и бизнес будут обсуждать ИИ в ближайшие годы: труд, налоги, энергетика, социальная политика, контроль над системами, международная координация. Очевидная претензия на участие в проектировании институтов.
Если сжать текст до крупных блоков, OpenAI предлагает следующее.
Труд и доступ. Работникам предлагают дать формальный голос при внедрении ИИ. Школам, библиотекам, малому бизнесу и небогатым регионам хотят расширить доступ к базовым ИИ-возможностям. В этом же блоке идут выплаты при всплесках кризиса на рынке труда, проекты 32-часовой недели и идея превращать прирост эффективности в деньги для сотрудников.
Перераспределение. Документ предлагает перестраивать налоговую базу, когда доход смещается из зарплат в капитал, корп. прибыль и автоматизацию. Отдельно обсуждается Public Wealth Fund, через который гражданам можно возвращать часть выгоды от ИИ-роста. Безусловный базовый доход, короче.
Инфраструктура. OpenAI прямо пишет, что дата-центры должны платить за свой аппетит без скрытого субсидирования со стороны домохозяйств. Параллельно предлагается ускорять расширение сетей и передающей инфраструктуры.
Контроль и управление рисками. Для мощных моделей предлагаются подтверждение происхождения, журналы аудита, специальные режимы проверки, инструкции по локализации угроз, ограничители при использовании ИИ государством и механизмы общественного участия в настройке этических рамок.
Содержательно в этом документе есть сильные места. OpenAI признает, что рост производительности сам по себе не гарантирует роста благосостояния большинства. Компания допускает сценарий, в котором выгоды ИИ концентрируются внутри узкого круга фирм, а работники оказываются в большей турбулентности без симметричного профита.
Но не стоит заблуждаться, перед нами не утопический текст с щенячьими глазами Альтмана. Весь этот труд хорошо работает в пользу самой OpenAI (иначе бы его не было):
1. Ускорение считается базовым сценарием. Документ обсуждает управление последствиями, смягчение издержек, перераспределение и безопасность. Вопрос о том, насколько сама гонка за все более мощными моделями оправдана, почти не затронут. Для OpenAI и ко это комфортная стартовая позиция.
2. Проблема концентрации описана в логике последующего перераспределения. Сначала несколько компаний получают вычислительную мощность, лучших исследователей, доступ к госконтрактам и контроль над инфрой. А потом государству предлагается придумать налоги, фонды и компенсации, чтобы вернуть обществу часть выгод. Такая рамка почти не дизраптит структуру рынка, на которой выросли сами ИИ-лаборатории.
3. Идея специальных правил для самых мощных систем выглядит разумно, но одновременно создает институциональный барьер вокруг нескольких игроков. Массовый слой приложений и более слабых моделей остается сравнительно не затронутым. Верхний этаж рынка обрастает аудитами, доверенными институтами, сложными процедурами и особым статусом. Такая архитектура снижает риски. Одновременно она закрепляет иерархию.
4. OpenAI явно хочет участвовать в создании законодательной среды. В финале документа компания предлагает гранты и до $1 млн в API кредитах для тех, кто будет развивать эти идеи дальше. Это все то же хорошо знакомое компании влияние на круг экспертов, на повестку обсуждения и на список вопросов, которые будут считаться центральными.
Документ стоит читать внимательно и с холодной головой. В нем много конкретики, местами больше, чем ожидаешь от корпоративного текста. При этом перед нами попытка заранее описать будущий порядок так, чтобы главная роль крупнейших компаний выглядела естественной, полезной и безальтернативной. Пчелы не против меда.
Вчера утёк полный исходный код Claude Code, а я взял и сделал in-depth техническую документацию по архитектуре и внутренностям CC — на основе анализа 1 884 файлов и 512 тыс. строк TypeScript. Должно быть полезно любому, кто использует CC как инструмент в своём пайплайне.
Публичная дискуссия по инерции сосредоточена на вопросе о том, когда машина окончательно превзойдет человека в интеллектуальной деятельности. Для практики этот вопрос уже не главный. Перелом происходит раньше: когда заметная часть интеллектуальных операций выходит за пределы индивидуального сознания и превращается во внешний вычислительный ресурс, доступный по запросу.
После этого меняется сама процедура решения задачи: сначала вызывается внешний контур рассуждения, затем человек проверяет, отбирает, исправляет и собирает итоговую позицию.
Порог уже пройден.
Интеллект начинает работать как инфраструктура. Эта перемена затрагивает производство знания, организацию интеллектуального труда и критерии профессиональной ценности.
Хороший язык для описания этого сдвига дает статья Стивена Шоу и Гидеона Наве из Уортона. Авторы расширяют классическую двухсистемную модель мышления и вводят третий контур — внешнее искусственное рассуждение. В этой схеме искусственный интеллект выступает как участник процесса суждения: подает варианты, формирует первичную интерпретацию, задает направление поиска решения и временами занимает место внутренней рассудочной работы.
Центральное понятие статьи — «когнитивная капитуляция».
Так авторы называют ситуацию, в которой человек принимает вывод модели с минимальной критической переработкой и присваивает его как собственное решение.
За этим стоит серия из трех исследований: 1372 участника и 9593 наблюдения. Участники обращались к помощнику более чем в половине случаев. В первом исследовании доступ к точному помощнику повышал точность ответов на 25 процентных пунктов по сравнению с режимом без внешней помощи. Доступ к ошибающемуся помощнику снижал точность на 15 пунктов. В сводном анализе трех исследований вероятность правильного ответа была выше более чем в 16 раз, когда внешний контур выдавал корректный ответ, чем когда он выдавал ошибочный.
Во всех трех исследованиях использование внешнего контура повышало субъективную уверенность участников, в том числе тогда, когда помощник ошибался. Значит, менялось не только качество решения. Перестраивалась связь между истинностью ответа и чувством интеллектуальной надежности.
Авторы проверяли, можно ли ослабить этот эффект. Дефицит времени снижал базовую точность на 13,5 процентного пункта, но зависимость от качества внешнего помощника сохранялась. Денежное вознаграждение за точность и немедленная обратная связь улучшали результаты, но не устраняли проблему. Среди активных пользователей помощника точность при корректных подсказках выросла с 77,2 до 84,8 процента, а при ошибочных — с 26,8 до 40,6 процента.
Есть и различия между людьми. Более высокое доверие к искусственному интеллекту повышало склонность следовать его ответам. Склонность к аналитическому мышлению и более высокий уровень подвижного интеллекта действовали как защита. Когда внешний контур выдавал неверный ответ, в среднем 73,2 процента таких эпизодов заканчивались когнитивной капитуляцией.
Отсюда следует более широкий вывод о труде. Меняется стоимость самой интеллектуальной работы как фактора производства. Если формализация, синтез, первичная интерпретация, построение аргумента и черновое проектирование становятся дешевой услугой, редкостью перестает быть индивидуальная интеллектуальная мощность в прежнем смысле слова.
Для профессий умственного труда это означает структурное сокращение спроса на значительную часть человеческого участия.
Выше поднимаются другие способности: постановка задачи, дисциплина проверки, удержание контекста, различение существенного и несущественного, ответственность за итоговое решение. Поэтому центральным становится вопрос об автономии субъекта в условиях, когда рассуждение все чаще разворачивается во внешнем контуре.
Google Research, DeepMind и NYU представили TurboQuant, и это может оказаться одной из самых важных инфраструктурных работ года в AI.
На бумаге выглядит не слишком захватывающе: vector quantization, сжатие высокоразмерных векторов, теоретические гарантии. На практике речь идет о двух очень дорогих вещах: KV-cache у больших языковых моделей и векторном поиске.
И там, и там старая проблема одна и та же. Нужно ужать данные как можно сильнее, но не испортить геометрию векторов, то есть расстояния и скалярные произведения. Если испортить, начинаются проблемы с attention, retrieval, ранжированием и качеством ответа модели.
Именно сюда TurboQuant и бьет.
Авторы утверждают, что их метод почти подходит к теоретическому пределу по distortion rate. Проще говоря, к пределу того, насколько хорошо такие векторы вообще можно сжимать при заданной битности. Для академической работы тезис уже сильный.
У большинства практических схем здесь старый компромисс. Либо нужно тяжелое офлайн-обучение, калибровка и кодбуки, либо метод быстрый и удобный для онлайна, но качество сжатия так себе. TurboQuant пытается этот компромисс сдвинуть.
Причем проблема не только в потере качества. Google в своем блоге отдельно пишут о еще одной неприятной детали классического vector quantization: memory overhead. Вы вроде бы экономите биты, но потом вынуждены тратить часть этой экономии на хранение quantization constants в полной точности для маленьких блоков данных. По их словам, такой overhead может добавлять еще 1-2 бита на число. То есть часть выигрыша просто съедается служебной нагрузкой.
На этом фоне TurboQuant выглядит как попытка решить сразу весь пакет проблем: уменьшить память, убрать лишний overhead, не требовать обучения или fine-tuning и при этом не развалить downstream-задачи.
Отдельно важно, что paper не сводит все к MSE. Для современных моделей этого недостаточно. В attention и retrieval критично сохранять inner product. Авторы прямо показывают, что quantizer, оптимизированный только по MSE, может давать смещенную оценку скалярного произведения. Поэтому у них двухшаговая схема: сначала основное сжатие, потом 1-битная коррекция остатка через QJL, чтобы убрать bias.
Если перевести это на нормальный язык, мысль простая: ужать вектор мало. Нужно сделать это так, чтобы модель после этого не начинала думать немного не о том.
По заявленным результатам картина выглядит сильно. В paper авторы пишут, что для KV-cache достигают quality neutrality на 3.5 битах на канал и лишь небольшую деградацию на 2.5 битах. В Needle-in-a-Haystack, по их данным, TurboQuant сохраняет качество полноточной модели при 4x-сжатии. На LongBench вариант с 3.5 битами идет практически вровень с full cache на Llama-3.1-8B-Instruct.
Но в блоге Google есть, возможно, еще более важный тезис. Там они отдельно подчеркивают, что TurboQuant умеет сжимать KV-cache до 3 бит без training и fine-tuning и без просадки качества на их тестах. Более того, они утверждают, что 4-bit TurboQuant дает до 8x ускорения при вычислении attention logits на H100 по сравнению с 32-bit unquantized keys.
Это прямой разговор про цену и скорость serving.
Не менее любопытна часть про vector search. Авторы утверждают, что TurboQuant обходит Product Quantization и RabitQ по recall, а время индексации у него почти нулевое. Для систем, где нужно хранить и искать по огромным индексам эмбеддингов, это потенциально очень большие деньги.
При этом голову терять, конечно, не стоит. Это история с очень сильными заявлениями, а значит тут особенно важна внешняя репликация. Формулировки вроде zero accuracy loss, near-optimal distortion и up to 8x всегда нужно проверять на деталях реализации, baseline и настройках эксперимента.
Но в сухом остатке новость действительно большая.
Если внешняя проверка подтвердит хотя бы большую часть заявленного, это будет одна из самых важных инфраструктурных работ в AI за последнее время.
Когда говорят «AI-агент с памятью», многие представляют себе одну векторную БД и магический retrieval. На практике этого почти никогда не хватает.
У Волны, моего Telegram-агента, память устроена как несколько разных слоев. Потому что в реальном диалоге нужно решать сразу три задачи: хранить долгие факты, держать под рукой недавний контекст и не забивать модель лишними токенами.
Условно память Волны состоит из 4 частей:
- Постоянные блоки в Letta. Это два базовых блока примерно по 3 тысячи символов каждый.
Первый — портрет пользователя: кто он, чем занимается, что для него важно, какие у него интересы и устойчивые контексты.
Второй — профиль самой Волны: стиль общения, поведенческие правила, как она реагирует на поправки и что считает важным в диалоге.
- Архивная память. Это слой для подробных фактов, которые не нужно держать в prompt постоянно, но важно уметь быстро находить. Поиск семантический, поверх него есть переранжирование по свежести, чтобы старый, но похожий факт не перебивал более актуальный.
- Ежедневный эпизодический лог. После каждого диалога система вытаскивает короткие факты и пишет их в markdown-файл. Туда попадают решения, предпочтения, явные реакции. При старте новой сессии в контекст возвращаются только последние 3 дня и только в сжатом виде.
- Граф связей в Neo4j. Отдельно строится сеть сущностей: люди, проекты, компании, темы, инструменты, события. Если я в сообщении упоминаю что-то знакомое, Волна пытается поднять связанные сущности и отношения вокруг него. По сути, это слой не «памяти фактов», а «памяти структуры».
Ключевая идея в том, что эти слои подмешиваются в модель не одинаково.
Когда сессия сбрасывается или контекст ужимается, Волна собирает картину заново. А на обычном ходе она не тащит весь memory dump, а использует базовый кэш и динамический контекст сообщения.
Это важно и для качества, и для скорости. Если всегда скармливать модели всю память целиком, она начинает тонуть в собственном прошлом. Если, наоборот, держать только один короткий summary, теряется ощущение непрерывности общения.
Отдельно мне нравится, как устроено обновление памяти после ответа. Оно идет асинхронно, в фоне. То есть пользователь уже получил сообщение, а система параллельно делает несколько вещей: - извлекает факты из обмена, - дописывает дневной лог, - отправляет диалог в Letta для обновления долговременной памяти - и обновляет граф сущностей.
Причем там есть несколько полезных ограничителей. Например, слишком короткие обмены вообще могут не попадать в извлечение фактов. А количество фактов зависит от длины диалога. Это простая вещь, но она хорошо защищает память от шлака.
Еще один важный слой — snapshots сессий. Когда разговор заканчивается, система сохраняет короткий JSON-снимок: summary, последние реплики, число ходов, иногда наблюдения про настроение или поведенческий паттерн. При следующем reset этот снимок можно один раз вернуть в контекст и получить ощущение, что агент не «проснулся с чистого листа».
Отдельно у Волны есть слой рефлексии поверх памяти.
Если вопрос звучит как «как у Влада менялось отношение к работе» или «какая у него траектория по здоровью», простой поиск уже слабоват: он возвращает куски, а не понимание.
Для этого есть memory_reflect. Он сначала поднимает набор релевантных воспоминаний через семантический поиск, затем передает их в модель с отдельной задачей собрать из разрозненных записей связный нарратив. На выходе получается короткая интерпретация на 2-5 абзацев.
Ну и, конечно, память нужно обслуживать. Иначе любая memory system быстро превращается в цифровой чулан. Поэтому отдельный maintenance-процесс.
Если совсем коротко, память Волны — это не один prompt, не одна база и не один retrieval. Это маршрутизация разных типов памяти с разным сроком жизни, разной ценой и разным способом инъекции в контекст.
AI-агентов, которые умеют что-то делать, уже хватает. Открыть браузер, прокликать сайт, отправить письмо, сходить в API, запустить workflow — это больше не выглядит как дифференциатор.
Интереснее другое: что вообще делает ассистента персональным.
Я строю такой ассистент — Volna. Он живёт в Telegram, работает 24/7 на сервере и задуман не как очередной task runner, а как постоянный слой между мной и повседневным потоком сообщений, напоминаний, спама, заметок, health-данных и прочего.
Ключевой вопрос для personal AI сейчас, как мне кажется, уже не в том, умеет ли система действовать. А в том, что она помнит, как выбирает момент и насколько хорошо встроена в реальные каналы жизни.
Вкус — это память
У большинства AI-ассистентов память до сих пор устроена примитивно: накопили факты, заэмбедили текст, потом по запросу достали что-то похожее.
На короткой дистанции это работает. На длинной — начинает шуметь. Поэтому у Volna память разделена на три слоя.
Первый — компактный постоянный профиль: устойчивые предпочтения, отношения, повторяющиеся интересы, особенности поведения. Второй — недавний эпизодический слой: rolling log последних дней, который даёт непрерывность и убирает эффект, будто каждый разговор начинается с нуля. Третий — архивный слой для точных ссылок, дат, старых деталей и разовых фактов. Он не подмешивается в каждый запуск, а достаётся только по необходимости.
То есть память здесь — курируемая система с разными режимами доступа.
Вкус — это тайминг
Хороший ассистент должен уметь не только писать, но и молчать.
В Volna это отдельная часть логики. Если плановая проверка не находит ничего действительно полезного, система возвращает no_message. А еще некоторые сценарии полезны, но не всегда уместны: например, регулярные вопросы для профилирования или напоминания. Поэтому их можно не просто выключить, а отложить — Volna сама поймет, когда можно продолжить.
Вкус — это среда выполнения
Volna живёт в Telegram не только как бот, но и имеет доступ к моему личному аккаунту. Это принципиально меняет класс задач.
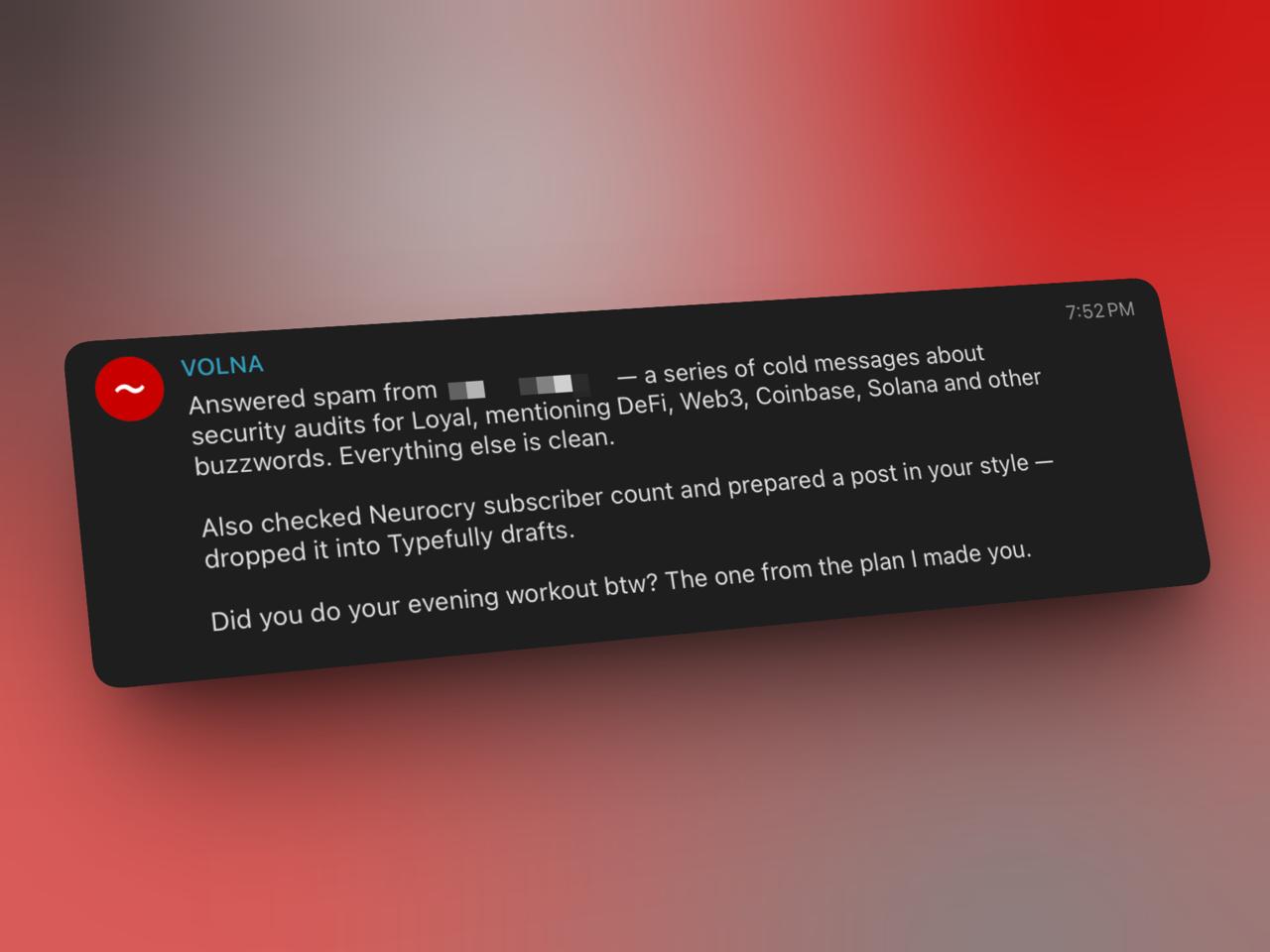
Она может работать внутри реального потока (ну волна же): фильтровать входящие, проверять на спам, искать по переписке, анализировать медиа, пересылать сообщения и в некоторых случаях отвечать от моего имени.
Например, если во входящих очевидный crypto-спам, Volna может ответить что-то вроде "это ассистент Влада, я передам сообщение".
Ещё у Volna есть свой Twitter.
Вкус — это не количество интеграций, а их связность
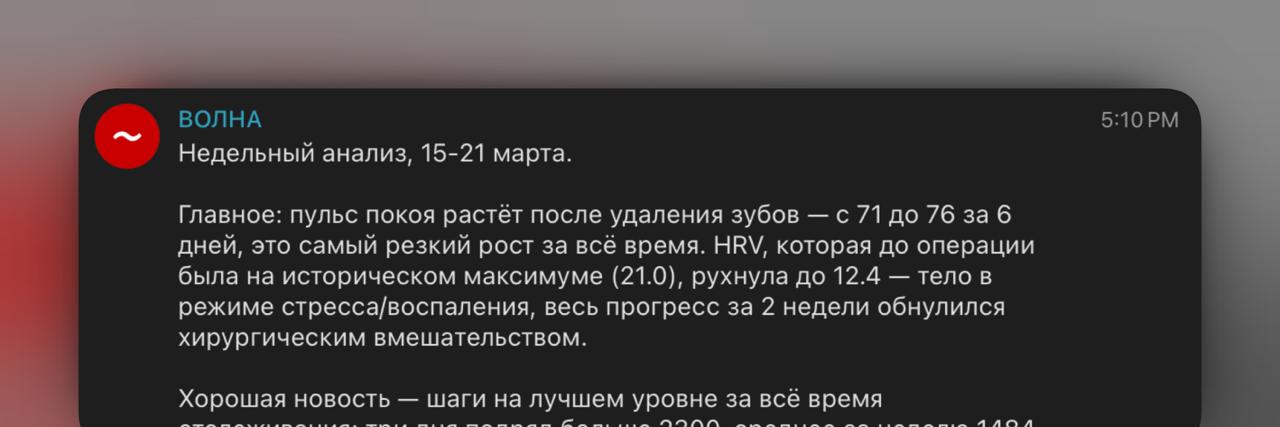
Отдельная часть Volna — health tracking.
Она синхронизирует данные Fitbit: сон, пульс, HRV, SpO2, температуру кожи, readiness, активность и другие метрики. Параллельно логирует еду по фото и отслеживает лекарства. Смысл в том, чтобы связать источники полезный контекст: проседает ли восстановление, сочетается ли недосып с ухудшением питания, и стоит ли вообще про это сообщать сейчас.
Вкус — это явное поведение
Ещё одно решение, которым я доволен, — как организованы skills и tools, которые подгружаются по требованию через суб-агентов. Система точно знает, когда искать в памяти, как использовать Spotify, Todoist, Workflowy, Typefully и прочие сервисы. Это делает поведение максимально редактируемым и детерминированным.
А еще Volna имеет доступ к собственному коду, периодически себя дебажит и вносит улучшения. Самостоятельно.
Вкус — это наблюдаемость
Вокруг Volna я собрал dashboard: логи, историю сессий, вызовы инструментов, состояние расписаний, deferrals, здоровье процессов, токен-статистику и метрики памяти.
Если ассистент действует от моего имени, он не должен быть чёрным ящиком.
--- Мне кажется, главная проблема personal AI сейчас не в автономности.
Она во вкусе. В том, что помнить. Когда говорить. Когда молчать. Что считать важным.
И как собирать из памяти, тайминга, каналов и инструментов что-то действительно персональное, а не просто ещё один productivity-слой с чатиком сверху.
Нейросети уже управляют вашим миром. Но, возможно, не так, как вы думаете.
Когда говорят об опасности ИИ, обычно рисуют две картинки. Первая — скучная: нейросеть ускорит работу, заменит часть профессий, сократит издержки, а дальше как-нибудь разберёмся. Вторая — кинематографическая: сверхразум, манипуляции, катастрофа, кнопка запуска конца света.
Обе картинки удобны. Обе помещают проблему куда-то вперёд. Но неприятная новость в том, что главная победа ИИ уже здесь.
Не в виде робота с красными глазами. Не в виде безработицы по щелчку. Она выглядит гораздо прозаичнее: как аккуратно написанный абзац текста.
Текст — самый коварный формат
С картинкой попроще. Шесть пальцев, медведь варит борщ — мозг получает сигнал: передо мной фейк. С видео тоже учимся быть осторожнее.
А текст — идеальный контрабандист.
Если он складный, уверенный и написан без явной дури, большинство людей не пойдёт перепроверять, что ускорение свободного падения не равно 11, что "полезно съедать по камню в день" — не медицинская рекомендация, и что список источников вообще существует. Машина транслирует чушь с интонацией справочника.
Новый авторитет
У нас в голове сидит старый баг: компьютер прав, потому что он компьютер.
Есть формула в Excel — значит, где-то есть строгая логика. Если ответ выглядит гладко — значит, он на что-то опирается. Если ИИ сказал уверенно — значит, "что-то знает".
Но LLM — это вероятностная машина по сборке правдоподобных фраз. Проблема в том, что люди часто читают это как новый тип авторитета.
И исследования об этом тоже говорят. В работе Microsoft Research с 319 "работниками сферы знаний" более высокая уверенность в GenAI была связана с меньшим объёмом критического мышления, а сама работа с ИИ часто смещалась от самостоятельного анализа к верификации готового ответа.
В ряде экспериментов люди вообще воспринимали AI-источник как менее предвзятый, более информативный и менее заинтересованный в убеждении, чем человек. То есть сама "нечеловечность" системы у многих повышает кредит доверия.
Мы начинаем думать внутри чужой рамки
Что дальше — а дальше люди ретранслируют ответы моделей как собственные выводы. Не потому что они глупые. Потому что так дешевле по усилию.
Так возникает очень странная форма зависимости: мы вроде бы всё ещё говорим сами, но всё чаще — словами, логикой и рамками, которые заранее предложила машина.
И здесь даже маркировка "это написал ИИ" помогает слабо. В эксперименте на 1601 участнике такие метки почти не меняли ни убедительность сообщения, ни оценку его точности, ни готовность делиться им дальше. Иными словами, сам факт искусственного происхождения текста не делает людей заметно осторожнее.
Самоусиливающаяся дурнота
Дальше запускается самый опасный механизм — петля обратной связи.
Модель ошибается → Человек копирует ошибку в пост, заметку, комментарий, SEO-текст, реферат, презентацию → Эта масса текста оседает в интернете → Следующая модель учится уже на мире, где выдумка статистически выглядит как нормальная часть реальности.
В работе Shumailov такой процесс описывается как model collapse: при рекурсивном обучении на сгенерированных данных модели начинают терять хвосты распределения и всё хуже отражают исходную реальность, при этом сохраняя видимость нормальной работы. То есть деградация может быть тихой и почти незаметной.
ИИ не обязан стать разумнее человека, чтобы начать формировать реальность. Ему достаточно стать массовым, удобным и достаточно убедительным.
Не конец света. Конец света хотя бы заметен. А здесь всё происходит в комфортном режиме. Вы не лежите под руинами цивилизации. Вы просто живёте в мире, где истина всё чаще определяется не проверкой, а убедительностью формулировки. И где глубина понимания постепенно подменяется доступом к более дорогой, более быстрой, более “умной” модели.